Introduction
Retrieval-Augmented Generation (RAG) has emerged as one of the most powerful patterns for building AI systems that combine the reasoning capabilities of Large Language Models with domain-specific knowledge. However, moving from a proof-of-concept to a production-grade RAG system requires careful consideration of architecture, performance, cost, and reliability.
In this guide, we'll walk through the essential components and best practices for building RAG pipelines that can handle real-world production workloads.
RAG Architecture Overview
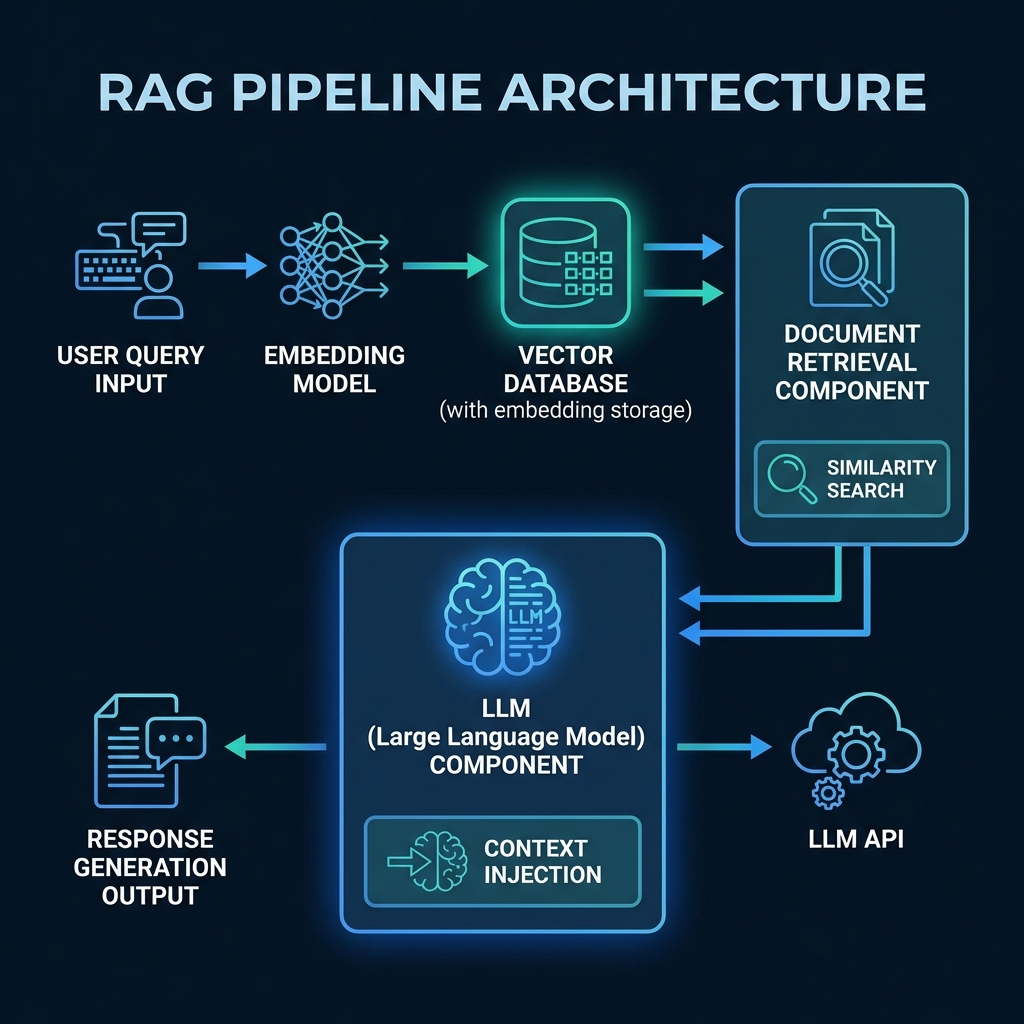
A production RAG pipeline consists of several critical components working in harmony. Let's break down each component and understand its role in the system.
Core Components
1. Embedding Model
The embedding model is responsible for converting text into dense vector representations. Your choice here significantly impacts both quality and cost.
from sentence_transformers import SentenceTransformer
# Production-grade embedding model
model = SentenceTransformer('all-MiniLM-L6-v2')
def embed_text(text: str) -> list[float]:
"""Convert text to embedding vector"""
return model.encode(text).tolist()Key Considerations:
- Model Selection: Balance between quality (OpenAI's text-embedding-3-large) and cost/latency (sentence-transformers)
- Dimension Size: Higher dimensions (1536+) improve accuracy but increase storage and search costs
- Caching Strategy: Cache embeddings for frequently accessed content to reduce API costs
2. Vector Database
The vector database stores embeddings and enables fast similarity search at scale. This is the heart of your retrieval system.
import pinecone
# Initialize Pinecone
pinecone.init(
api_key="your-api-key",
environment="us-west1-gcp"
)
# Create index with optimized settings
index = pinecone.Index("production-rag")
# Upsert with metadata for filtering
index.upsert(vectors=[
{
"id": "doc-123",
"values": embedding,
"metadata": {
"source": "technical-docs",
"timestamp": "2026-01-20",
"category": "ai-systems"
}
}
])Production Best Practices:
- Index Organization: Use namespaces to separate different content types or tenants
- Metadata Filtering: Leverage metadata for pre-filtering to reduce search space
- Hybrid Search: Combine vector similarity with keyword matching for better relevance
- Monitoring: Track query latency, recall metrics, and index freshness
3. Document Retrieval
Retrieval quality directly impacts your LLM's ability to provide accurate answers. A sophisticated retrieval strategy is crucial.
def retrieve_context(
query: str,
top_k: int = 5,
diversity_threshold: float = 0.7
) -> list[dict]:
"""
Retrieve relevant documents with diversity filtering
"""
# Generate query embedding
query_embedding = embed_text(query)
# Retrieve candidates (fetch more than needed)
candidates = index.query(
vector=query_embedding,
top_k=top_k * 3,
include_metadata=True
)
# Apply diversity filtering
diverse_results = apply_mmr(
candidates,
lambda_param=diversity_threshold
)
return diverse_results[:top_k]Advanced Retrieval Techniques:
- Maximal Marginal Relevance (MMR): Balance relevance and diversity to avoid redundant context
- Re-ranking: Use a cross-encoder model to re-rank top candidates for improved precision
- Query Expansion: Generate multiple query variations to improve recall
- Contextual Compression: Summarize retrieved documents to fit more relevant information in context window
4. LLM Integration
The LLM consumes retrieved context and generates responses. Proper prompt engineering and error handling are critical.
from openai import AsyncOpenAI
import asyncio
client = AsyncOpenAI()
async def generate_response(
query: str,
context: list[dict],
max_tokens: int = 1000
) -> str:
"""
Generate LLM response with retrieved context
"""
# Format context
formatted_context = "\n\n".join([
f"Source {i+1}: {doc['text']}"
for i, doc in enumerate(context)
])
# Construct prompt
prompt = f"""Use the following context to answer the user's question.
If the answer cannot be found in the context, say so clearly.
Context:
{formatted_context}
Question: {query}
Answer:"""
# Call LLM with retry logic
response = await client.chat.completions.create(
model="gpt-4-turbo-preview",
messages=[
{"role": "system", "content": "You are a helpful AI assistant that answers questions based on provided context."},
{"role": "user", "content": prompt}
],
max_tokens=max_tokens,
temperature=0.3 # Lower temperature for factual responses
)
return response.choices[0].message.contentProduction Considerations
Cost Optimization
RAG systems can become expensive at scale. Here's how to optimize:
- Semantic Caching: Cache responses for semantically similar queries (can reduce LLM costs by 70%+)
- Smart Token Management: Compress context to use fewer tokens while maintaining relevance
- Tiered Models: Use cheaper models for simple queries, reserve GPT-4 for complex ones
- Batch Processing: Process multiple queries together when latency allows
Observability & Monitoring
You can't improve what you don't measure:
- Retrieval Metrics: Track precision@k, recall@k, and MRR (Mean Reciprocal Rank)
- LLM Metrics: Monitor response quality, hallucination rate, and citation accuracy
- Performance: P95/P99 latency, throughput, and error rates
- Business Metrics: User satisfaction scores, conversation completion rates
Data Quality & Freshness
Your RAG system is only as good as your data:
- Ingestion Pipeline: Automated, idempotent document processing with error handling
- Chunking Strategy: Optimal chunk size (512-1024 tokens) with overlap for context preservation
- Version Control: Track document versions and maintain audit trails
- Real-time Updates: Incremental updates for time-sensitive information
Deployment Architecture
# Kubernetes deployment example
apiVersion: apps/v1
kind: Deployment
metadata:
name: rag-api
spec:
replicas: 3
template:
spec:
containers:
- name: rag-service
image: coresyntax/rag-api:v1.2.0
resources:
requests:
memory: "2Gi"
cpu: "1000m"
limits:
memory: "4Gi"
cpu: "2000m"
env:
- name: EMBEDDING_MODEL_CACHE
value: "/cache"
- name: MAX_CONCURRENT_REQUESTS
value: "100"
volumeMounts:
- name: model-cache
mountPath: /cacheConclusion
Building production-ready RAG systems requires more than just connecting an LLM to a vector database. Success comes from careful attention to architecture, cost optimization, quality metrics, and operational excellence.
The patterns and practices outlined here represent battle-tested approaches from real-world deployments. Start with the basics, measure everything, and iterate based on your specific use case and constraints.
Key Takeaways
- Choose embedding models based on the latency-quality-cost tradeoff for your use case
- Implement sophisticated retrieval strategies beyond simple similarity search
- Monitor both system metrics and business outcomes
- Optimize costs through caching, compression, and smart model selection
- Maintain data quality with robust ingestion and versioning pipelines